

Sin importar cuan diferentes seamos los seres humanos, todos compartimos el 99.9 % de la totalidad del material genético o genoma; en el 0.1 % restante se encuentran las características heredadas que hacen diferente a cada individuo y también en esa pequeña fracción genética se encuentra lo que hace distintas biológicamente a las diversas etnias, por ejemplo, el color de piel y ojos.
Thank you for reading this post, don't forget to subscribe!Igualmente, ahí se localizan los factores genéticos que significan riesgos y predisposición que hacen susceptibles a las y los mexicanos a ciertas enfermedades comunes como el cáncer de mama, la obesidad, hipertensión y diabetes, pero también la susceptibilidad o resistencia a ciertos medicamentos.
La identificación y el conocimiento de estas singularidades genéticas es el objetivo del proyecto “oriGen” del Tecnológico de Monterrey, que luego de dos años y medio culminó la etapa de recopilación de muestras de ADN de 100 mil personas mexicanas de 19 estados y 17 ciudades del país.
En lo que constituye la investigación más ambiciosa de México y América Latina en el campo de la genómica, a partir del ADN extraído de una pequeña muestra de sangre donada por cada una de las personas participantes, el equipo de científicos del TecSalud del Tec de Monterrey, encabezado por Pablo Kuri, llevará a cabo el análisis del genoma de las poblaciones mexicanas.
“Hemos terminado una primera etapa del proyecto iniciado en 2019, que es la recolección genética de muestras de sangre de 100 mil personas: eso nos tomó menos tiempo de lo estimado”, afirma Pablo Kuri, director del proyecto oriGen. “Ya tenemos la base de datos de 100 mil individuos, y ahora estamos en el proceso del primer acercamiento –en el primer semestre de 2026– hacia la información genética que debemos procesar”.

el proyecto “oriGen”, del Tecnológico de Monterrey, busca La identificación y el conocimiento de las singularidades genéticas de 100 mil personas mexicanas de 19 estados y 17 ciudades del país.
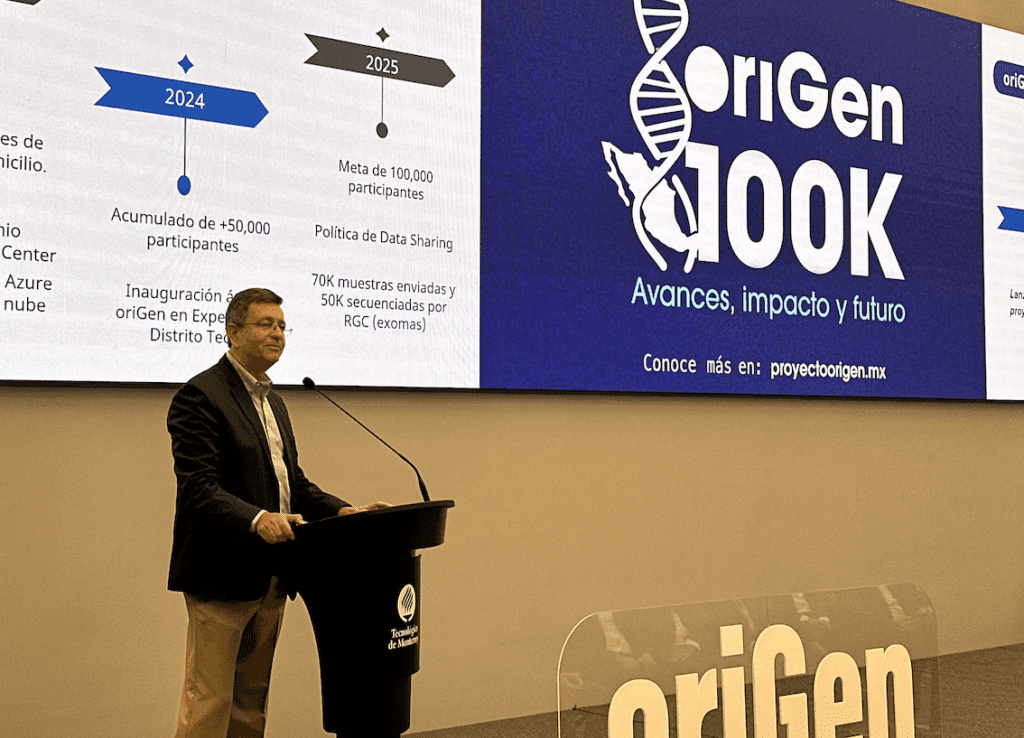
Entre las metas del proyecto se encuentra el obtener 10 mil genomas completos y 100 mil exomas (la parte del ADN que codifica o produce las proteínas de todo el organismo), lo que conforma el análisis genómico más grande llevado a cabo hasta ahora en América Latina.
Guillermo Torre, rector de TecSalud e iniciador del proyecto, afirma que una de las prioridades estratégicas en salud hacia 2030 es impulsar la investigación aplicada y oriGen generará conocimiento de valor. “Lo que sigue es igual de relevante: el análisis, la secuenciación, la generación de conocimiento y, lo más importante, su aplicación para mejorar la prevención, el diagnóstico y el tratamiento de enfermedades que afectan a millones de personas”.
OriGen obtendrá información genómica escasa a nivel internacional, ya que menos del 2 % de las investigaciones en este campo en todo el mundo se lleva a cabo en poblaciones latinoamericanas. Como lo comenta Pablo Kuri, epidemiólogo y quien impulsó políticas públicas en el campo de la salud en diversos puestos en más de 30 años en la administración pública: “Hay un desconocimiento del componente genético de nuestras poblaciones, ya que el 95 % de las investigaciones se realizan en poblaciones caucásicas; el 2 % o 3 % se hace en poblaciones asiáticas y muy poco en poblaciones africanas y latinoamericanas”.
El ADN de las 100 mil personas se combinará con la información clínica, epidemiológica, biométrica y metabólica que se obtuvo de cada una de las personas que participaron, con lo que se conformará la base de datos genética, epidemiológica, clínica y médica más grande del país.
“Hoy las poblaciones nos regalan una fuente de información importante contenida en la sangre y también sobre su susceptibilidad, su pasado, las enfermedades o problemas de salud que padece y su estilo de vida que nos sirven para poder hacer una asociación biológica y estadística con la información genética; nos aportan un conjunto de información muy enriquecedora”, señala Víctor Treviño, director científico de oriGen.
Este proyecto permitirá conocer y comparar las diferencias de nuestros genes con las de otras poblaciones del mundo, comprender cómo esas variaciones influyen en nuestra salud y utilizarla de forma integral para orientar mejor los tratamientos terapéuticos que tanto promete la medicina genómica.
“Lo que sigue es igual de relevante: el análisis, la secuenciación, la generación de conocimiento y, lo más importante, su aplicación para mejorar la prevención, el diagnóstico y el tratamiento de enfermedades que afectan a millones de personas”: Guillermo Torre, rector de TecSalud e iniciador del proyecto origen.

Genoma y pangenoma humanos
Hace 24 años, el 16 de febrero de 2001, se publicó el primer borrador del Genoma Humano, uno de los primeros hitos de la ciencia del siglo XXI. Un punto de inflexión para las ciencias biológicas, biomédicas y la bioeconomía que ha marcado el rumbo de la ciencia y la tecnología actuales y domina buena parte de la economía mundial.
Con ese proyecto llevado a cabo en Estados Unidos se pudieron descifrar los más de tres mil 200 millones de pares de bases de nucleótidos (adenina A, citosina C, guanina G y timina T), que conforman los más de 20 mil genes humanos –muchos todavía desconocidos–, que se empaquetan en los 23 pares de cromosomas en el núcleo de cada célula del organismo humano.
La secuenciación o desciframiento significa determinar el orden exacto de los pares de bases de la molécula de ácido desoxirribonucleico o ADN (A siempre emparejada con T, y C siempre con G), que contiene la información genética en todos los seres vivos y que está formada por dos cadenas que se enrollan entre sí para formar una estructura de doble hélice –similar a una escalera de caracol microscópica.
La secuenciación o desciframiento tomó 13 años e inició en los Institutos Nacionales de Salud (NIH, por sus siglas en inglés) de EE. UU., encabezado por Francis Collins, y posteriormente se sumó la empresa Celera Genomics, al mando de Craig Venter, lo que aceleró y mejoró el desciframiento del genoma. En total, participaron 2 mil 400 investigadores de seis países y tuvo un presupuesto de 2 mil 700 millones de dólares.
De hecho, hasta el 2022 el Consorcio Telómero a Telómero (T2T) terminó de secuenciar el 10 % del genoma humano que faltaba desde 2001. La mayor parte de ese ADN reside en los centrómeros (la sección central y densa de cada cromosoma) y los telómeros (los extremos largos de los cromosomas) que son las regiones genómicas más difíciles de secuenciar e incluyen algunos genes y grandes cantidades de ADN repetitivo.

El Genoma humano descifrado en 2001 ha sido la columna vertebral de la genómica en las dos últimas décadas, pero tiene una limitante muy importante: ha sido una herramienta deficiente, pues alrededor del 70 % de sus datos provienen de un solo individuo africano-europeo, que no representa a la diversidad genética humana.
Este mapa ha sido la columna vertebral de la genómica en las dos últimas décadas, pero tiene una limitante muy importante: ha sido una herramienta deficiente, pues alrededor del 70 % de sus datos provienen de un solo individuo africano-europeo, que no representa a la diversidad genética humana y se ha usado como referencia en casi todos los estudios genómicos, hasta ahora.
A nivel mundial, los estudios de genoma completo (GWAS, siglas en inglés de Estudios de Asociación de Todo el Genoma) tienen marcadas disparidades, ya que en solo el 5 % de los estudios genómicos está representada el 90 % de la población del planeta. Con el propósito de cambiar este panorama, en 2023 se publicó e primer borrador del Pangenoma Humano, que incluyó las secuencias del genoma de 47 personas ancestralmente diversas, llevado a cabo por un equipo internacional de más de 250 científicos, que conforman el Consorcio de Referencia del Pangenoma Humano y otras instituciones públicas.
Financiado por el Instituto Nacional de Investigación del Genoma Humano (NHGRI, por sus siglas en inglés), que forma parte de los NIH, el pangenoma tiene el objetivo de secuenciar el genoma de 350 personas étnicamente diversas para 2026. De esta manera se podría conformar una referencia mucho más diversa para diagnosticar enfermedades y guiar los tratamientos médicos con mayor precisión en el futuro.
“Los investigadores básicos y los médicos que utilizan la genómica necesitan acceder a una secuencia de referencia que refleje la notable diversidad de la población humana, lo que ayudará a reducir las posibilidades de propagar disparidades en la salud”, dice Eric Green, quien fue director del NHGRI de 2009 a 2025.
El proyecto oriGen también cumple con el objetivo de cambiar esta inequidad y desequilibrio genómico desde la diversidad genómica mexicana, cuya mezcla genética es de las más recientes en el mundo, con la llegada de los europeos hace 500 años.
Mejorar la diversidad global en todos los aspectos de la investigación genómica será crucial para avanzar en el conocimiento e implementar la medicina genómica de manera equitativa. Hasta ahora, se han secuenciado aproximadamente un millón de genomas humanos en todo el mundo y se proyecta que llegará a 100 millones para 2030, entre ellos las de los 100 mil mexicanas y mexicanos del proyecto oriGen.
A nivel mundial, los estudios de genoma completo (GWAS, siglas en inglés de Estudios de Asociación de Todo el Genoma) tienen marcadas disparidades, ya que en solo el 5 % de los estudios genómicos está representada el 90 % de la población del planeta.

Pequeñas grandes diferencias
Con la secuencia completa del genoma humano los científicos continuan trabajando para comprender cómo funciona, cuáles son las diferencias entre los genomas de las diversas poblaciones o entre individuos, cómo influye en la salud-enfermedad, y de qué manera esta información puede utilizarse para desarrollar tratamientos más precisos en la medicina.
El equipo de investigadores de oriGen espera identificar aquellas variaciones presentes en el 0.1 % del genoma que nos distingue a las poblaciones de prácticamente todo el país gracias al biobanco de las poblaciones mexicanas del TecSalud. En estudios previos que comparan la variación del ADN entre personas sanas y enfermas en México y otros países, se han identificado regiones del genoma asociadas con diversos padecimientos.
“Un pequeño cambio en una sola letra (A, T, C, G) de estas 3 mil 200 millones puede modificar la estructura tridimensional de una proteína y cambiarle la función completamente, y eso puede hacer que el sistema inmune de un individuo ya no funcione adecuadamente, que no pueda metabolizar bien un alimento o que se guarde en un tipo de grasas y no en otro”, detalla Víctor Treviño. “Un solo cambio, puede implicar modificaciones enormes sobre cómo se presenta una enfermedad”.
Si bien hay enfermedades complejas como la diabetes, obesidad e hipertensión que son multifactoriales, se podrán identificar algunos de esos componentes genéticos de predisposición, riesgo o resistencia en las poblaciones mexicanas.
En estudios genómicos que se están llevando a cabo en otras partes del mundo se han identificando diferencias que causan enfermedades, pero también se ha demostrado que influyen en la forma en que los fármacos se metabolizan o actúan en diferentes individuos e incluso en poblaciones étnicas. Un ejemplo de ello es un estudio genómico llevado a cabo en Corea del Sur que encontró una variante específica de su población en un gen que regula la metabolización de algunos medicamentos. Esta información es esencial para dosificar adecuadamente los fármacos y mejorar la respuesta a cada terapia específica.
Otro estudio llevado a cabo en Brasil, publicado este año, analizó más de dos mil genomas completos de sus diversas poblaciones con el que se descubrieron más de 8.7 millones de variantes genéticas exclusivas de los brasileños, entre ellas 36,000 potencialmente dañinas, algunas asociadas con afecciones como el colesterol alto, la obesidad y la malaria.
La secuenciación genómica también es fundamental para entender los mecanismos de acción de las enfermedades raras con las que ya se han desarrollado métodos de diágnostico temprano para algunas de ellas.
Pero con oriGen no solo se buscan elementos de riesgo, sino también agentes protectores de cierto tipo de genes que evitan el desarrollo de enfermedades en México. “Hay un factor que se describió que es muy raro en uno de los genes de poblaciones mexicanas que te protegen contra la obesidad”, señala Kuri. “Son muy pocos los individuos que lo tenen y no se ve en otras poblaciones. Ese es el tipo de cosas se podrán ir descubriendo e identificando en este proyecto”.

“Hoy las poblaciones nos regalan una fuente de información importante contenida en la sangre y también sobre su susceptibilidad, su pasado, las enfermedades o problemas de salud que padece y su estilo de vida que nos sirven para poder hacer una asociación biológica y estadística con la información genética; nos aportan un conjunto de información muy enriquecedora”: Víctor Treviño, director científico de oriGen.
Origen de las poblaciones
Otro aspecto que se desprenderá de oriGen se encuentra el estudio de las ancestrías de las poblaciones mexicanas, con lo que se podrá conocer la evolución de estos factores genéticos de predisposición o resistencia en poblaciones diversas como las mexicanas. De hecho, como parte del programa piloto de este proyecto, se analizó el genoma completo de 1,500 personas del Estado de Nuevo León y en este estudio se pudo identificar que existe un gradiente genético de poblaciones indígenas nativas que van desde un 40 % en el norte del país hasta un 80 % en sureste.
Pero además, Víctor Treviño pudo asociar esta ancestría con el factor Rh de la sangre, es decir, el tipo de proteína en la superficie de los glóbulos rojos que determina el tipo de sangre. El RH negativo es un tipo de sangre de baja frecuencia en México, con un 8 % de la población con RH negativo y en Europa es del 10 %.
Treviño y sus colaboradores pudieron asociar este tipo de sangre con un mayor componente de ancestría europea, mientras que un mayor componente de ancestría indígena el factor RH negativo es mucho más reducida. “Con estas investigaciones podremos saber el origen del RH negativo en el México quizá desde la Conquista, ya que es muy probable que no existiera antes”, afirma Treviño. “Estos son los primeros indicios de este programa genómico que nos puede ayuda a entender un poco de nuestra historia”.
En 2023, en la revista Nature se publicaron dos artículos genómicos realizados en nuestro país y de gran relevancia, el primero de ellos denominado el Biobanco de México, encabezado por Andrés Moreno Estrada, del Centro de Investigación y de Estudios Avanzados del Instituto Politécnico Nacional, en el que se analizó el ADN de 6 mil personas mexicanas de los 32 estados del país, con el que identificaron factores genéticos y ambientales asociados con el índice de masa corporal, triglicéridos, glucosa y estatura.

OriGen arrojará información novedosa que se sumará a los estudios previos sobre el genoma de las poblaciones mexicanas.
Asimismo, el Estudio Prospectivo de la Ciudad de México, en el que también participó Pablo Kuri, analizó muestras de más de 140,000 personas de dos alcaldías de la Ciudad de México con el que se descubrieron 31.5 millones de variantes genéticas exclusivas y se observó que el 66% de la ascendencia de esos capitalinos era indígena, la mayoría proveniente del centro de México.
OriGen arrojará información novedosa que se sumará a los estudios previos sobre el genoma de las poblaciones mexicanas; asimismo, constituye el banco genómico más grande de América Latina una herramienta necesarias para generar futuros tratamientos en la práctica clínica de la medicina de precisión o medicina genómica.